

Hello, I am Shikha, I work in the system department as an engineer.
GMO Research uses a variety of approaches to achieve scalability in order to handle millions of traffic daily.
When developing systems, it is important to be aware of scalability, and we believe it is essential knowledge to improve your own level of performance.
In this issue, we will introduce our research on achieving that scalability.
What is scalability?
Scalability is the property of a system to handle a growing amount of work.
※Wikipedia
Systems must be able to handle increasing volumes of users, data, and traffic without sacrificing performance or dependability. Systems that are expected to grow significantly, such as social networking platforms, e-commerce websites, and mobile apps, require the ability to scale in particular.
Engineers use a variety of methods to achieve scalability, including load balancing, caching, distributed file systems, and sharding, to achieve scalability.
Methods to Improve Scalability① Load Balancing
The system’s performance and availability are enhanced through load balancing. Load balancing is a method of distributing the load on the system among multiple servers to prevent a single server from being overwhelmed and to help the system as a whole handle an increase in traffic.
Load balancers can be hardware-based or software-based, and they can distribute the load using a variety of methods such as IP hash, least connections, and round-robin.
The system can handle more requests and respond more quickly by distributing traffic among multiple servers to prevent any one server from becoming overloaded. By automatically identifying when a server is down and diverting traffic to another accessible server, load balancers can also offer redundancy.
Utilizing a software-based load balancer such as NGINX or HAProxy is a popular method of load balancing.With the flexibility and simplicity these solutions offer, engineers can modify the load balancing algorithm to suit the requirements of the system. They can also be installed on virtual machines or containers, which makes horizontal scaling simple.
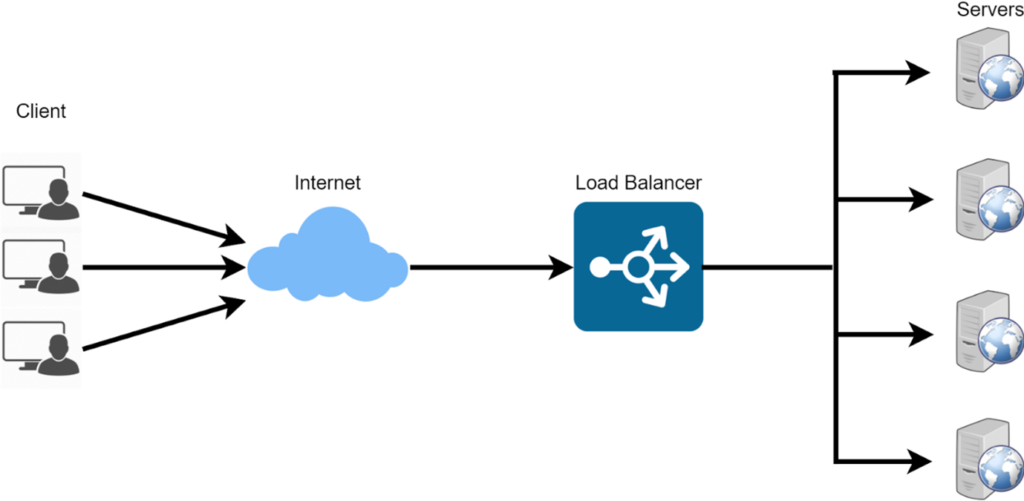
※cited from:「Distribute server load with Nginx load balancer」
Methods to Improve Scalability② Caching
As the number of users accessing the system increases, the overhead across multiple servers performing load balancing can increase, leading to slower response times. Therefore, using caching is an effective solution in this case.
Caching refers to keeping frequently accessed data in memory to reduce the load on the database and improve system speed.
Caching is a common strategy to improve system efficiency because it reduces the time it takes to retrieve data from the database. The system can reply to requests more quickly and decrease the user’s reaction time by storing frequently used data in memory. Additionally, caching lightens the stress on the database, enabling it to handle more requests.
Caching can take place at several system levels, including the application, web server, and database levels.
Caching can take many different forms, including in-memory caching, page caching, and CDN caching. Page caching involves caching the complete page output, whereas in-memory caching involves storing data in the application’s memory. To reduce the burden on the server, CDN caching involves storing static assets like photos and videos on a content delivery network (CDN).
However, implementing caching can be difficult since it necessitates making sure that the data in the cache is consistent and in sync with the database.

Methods to Improve Scalability③ Distributed File Systems
Distributed data store is a computer network where information is stored on more than one node, often in a replicated fashion.
※Wikipedia
As files can be viewed from any system machine, a distributed file system offers great availability and scalability. Hadoop Distributed File System (HDFS), Google File System (GFS), and Amazon S3 are some examples of distributed file systems.
Large amounts of data can be managed using distributed file systems because they can be accessed from any system machine. The system can manage more data than it could with a single machine by distributing files among several machines. Distributed file systems can also offer redundancy, making sure that files are still available even in the event that one or more machines fail.
For example, the Hadoop Distributed File System (HDFS), widely used in big data applications, is a well-known distributed file system.High availability and fault tolerance are features of HDFS, which is made to handle enormous amounts of data. Another illustration is the cloud-based object storage service Amazon S3, which can store and retrieve any volume of data and is very scalable.
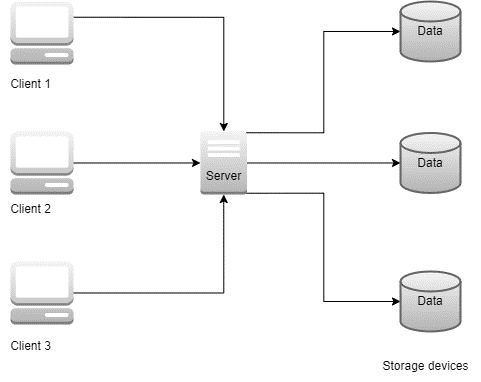
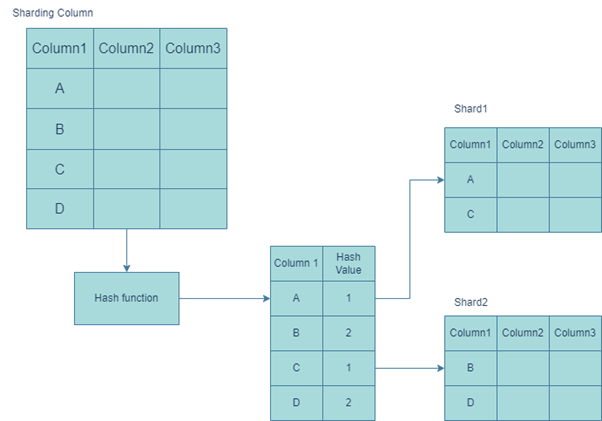
Methods to Improve Scalability④Sharding
Data is divided into smaller parts and distributed across other workstations using the database partitioning technique known as sharding. A subset of the data is stored on each machine, and the system can respond to queries by accessing the relevant shard. The system can manage massive volumes of data by using the horizontal scaling approach known as sharding, which distributes the data across numerous machines.
However, sharding introduces new difficulties, such as ensuring data consistency between shards. The system must retrieve the data from all pertinent shards and combine the results when a query requires data from several shards. When working with large data sets, this approach can be cumbersome and slow.
Sharding can be carried out in a variety of ways, including range-based, hash-based, and location-based sharding. Data is divided up depending on a range of variables, such as a customer ID or a date range, in range-based sharding. With hash-based sharding, a particular column, like a customer ID or a product ID, is used to fragment the data. Data is divided up based on the user or machine’s location when using location-based sharding.
Conclusion
Scalability is difficult to achieve yet is an important component of system design. To achieve scalability, engineers employ a variety of approaches like load balancing, caching, distributed file systems, and sharding. Understanding the trade-offs involved in selecting the best technique for a given system is critical, as each technique has its advantages and disadvantages.
It is critical to take the system’s requirements, architecture, and anticipated growth into account while designing a scalable system. Scalability should be incorporated into the system at the outset rather than being added later. In order to ensure that the system continues to scale successfully, it is also crucial to monitor its performance and make adjustments as necessary.
In conclusion, any system that is anticipated to experience significant growth must be scalable in order to succeed. Engineers can create systems that can handle growing volumes of traffic, data, and users without sacrificing performance or reliability by applying the principles covered in this article. It is possible to build systems that scale from zero to millions of users and beyond with careful planning and attention to detail.
Thank you for reading this article.
References:「System Design Interview」



テックブログサムネ-3-730x410.jpg)
テックブログサムネ-4-730x410.jpg)
テックブログサムネ-2-730x410.jpg)