

Hi everyone, My name is Rohit and I work in the Global Systems Department at GMO Research. My job is to build and maintain systems that are used to bridge the gap between the market and clients. I have been working here for almost 2 years now and I love to develop new features and work with peers who share the same goals as me, which is to become the No. 1 marketing solution platform in the world.
Background on the project
At the start of 2022, I received a message from my manager that I will be working on a new project. I was excited to hear that. I like working on projects as it requires planning and execution cycles. We plan and then we execute. Then we inspect and if changes are required we plan again and execute again and so on the cycle goes. I find it interesting to think of the goal and then see the steps that lead to that goal. I learned this from the GMO’s spirit venture – conclusion first approach.
Soon I came to know about the project details. The project was about developing a system that would read texts in Japanese, process it and then label it as either good or bad. Since this project requires the algorithm to understand texts in a specific language that a computer cannot understand, it falls under the category of NLP – Natural Language Processing. NLP is a component of Artificial Intelligence. It is the ability of a computer to understand languages just like humans. There are various steps involved in understanding a language right from the vast vocabulary to the combination of words. It is important to understand the meaning and sentiment behind the words to be able to understand it and classify it as good or bad. Let’s first learn some details about the project.
Project Details
What is the FA Check Automation?

The title of the project was “FA Check Automation”. Here FA means, Free Answer. In a survey, there are various types of questions and each question has its own way of requesting answers. Example, a Single Answer (SA) type question will accept a single answer out of a choice of answers. A Multiple Answer (MA) type question will accept multiple answers from the choice of answers displayed. However, there are times when we need input from the user as answers. These answers are called Free Answers.
So the project was about checking these Free Answers in an automated way. It is a huge task for a human to read all the answers one by one and check the appropriateness of the answers.
For a person to manually check and validate all Free Answers, it would take about a hundred of hours. But if a machine is able to do it, it can be automated and all those hundreds of man hours can be used to do more productive work. This was the main motivation of the project – “To improve the utilisation of time”.
Project Solution
Once the project was understood, it was time to figure out solutions.
We first started to explore Google’s AutoML feature. It provides a system where the user gives inputs with correct labels to a “Machine Learning” model to recognize and remember useful as well as bad patterns. Once the model is trained with labelled input data, the next step is to feed un-labelled input data to the model which then returns output texts classified with labels – good or bad.
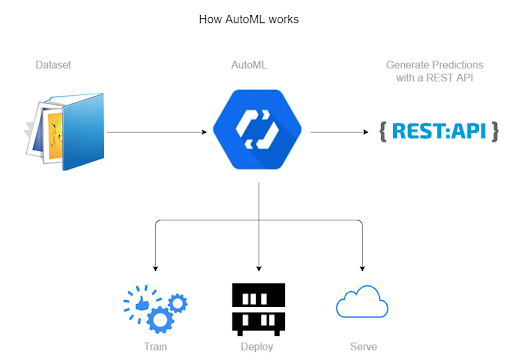
In order to judge whether AutoML provides us with a good solution or not, we used the “Cohen’s Kappa Coefficient”.
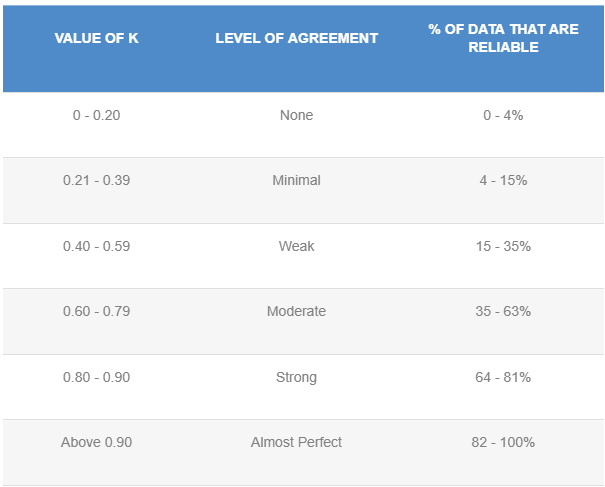
Kappa Coefficient:The degree of agreement between frequencies of two sets of data collected on two separate occasions can be technically understood by the Kappa Coefficient. This coefficient provides a good indication of the relationship between the actual and expected predictions.
After several training and testing sessions we saw some acceptable results. The accuracy of the model was fine and it was able to label texts. However there were several issues along with it –
1. Training time was very high.
2. Cost of using AutoML in production for a larger set of data was high.
3. The result was okay but could have been better in terms of the kappa correlation coefficient value. Kappa values obtained initially were low but finally we were able to get near about 0.6 which corresponds to moderate agreement.
So we began searching for other possible solutions.
One interesting fact is that the Japanese language is different from other languages in the sense that all the words are written consecutively without spaces. Also, we have to go through a process called “tokenizing” to convert the input text strings into a 2D vector array that maps all the characters and their combinations from the input text. It makes it difficult to tokenize and understand the words separately. While there are famous tokenizers that would help separate individual words from the sentence, it would increase processing time and use more memory to process the same sentence.
For this reason, we shifted to using Convolutional Neural Networks (also called CNNs) that work at Character Level. Such a method does not require knowledge of language semantics or syntax to classify the texts. This makes the implementation simpler, especially for the Japanese language as we eliminate the need to tokenize words. Since it reads each character and learns its combinations with other characters, it gives a calculated probability of whether a complete sentence falls under a certain label based on training data.
We decided to build this Character Level CNN Model using Tensorflow and Keras.
TensorFlow is an open-sourced end-to-end platform, a library for multiple machine learning tasks, while Keras is a high-level neural network library that runs on top of TensorFlow.
Both provide high-level APIs used for easily building and training models, but Keras is more user-friendly because it’s built-in Python.
It was my first time working with Tensorflow and Keras so I had to study it thoroughly before the implementation, to make efficient use of the model and generate accurate results.
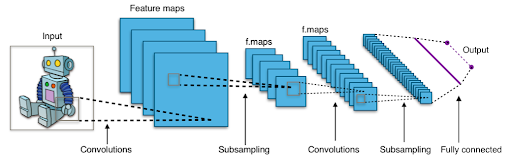
(Example of a CNN model using Tensorflow)
Source : https://en.wikipedia.org/wiki/Convolutional_neural_network#/media/File:Typical_cnn.png
Project Workflow
1. The first step was to understand and decide the input. It had to be compatible with the Tensorflow Model as well as MO(Market Observer). So we decided to use a .csv file with texts separated by the new line character (\n). This file is generated by MO Analysis(Systems for processing response data) and is then sent to the AI Model Server to do predictions.On the AI Model server, we use Python’s Pandas Library to read the csv and store texts in a dataframe object. If the csv file is too large, it will be read in chunks to save memory overflow.
|
1 2 3 4 5 6 7 8 9 10 |
# Read CSV in chunks dfs = pd.read_csv(file_path, names=['sentence'], sep='\n', engine='python', skip_blank_lines=False, na_filter=False, encoding='utf-8', iterator=True, chunksize=int(self.char_cnn_model.chunk_size)) for df in dfs: if df.empty: logger.error('File : %s is empty!', file_path) return -1 test_texts = np.array(df['sentence'].values) output_test_texts = test_texts |
We also made a provision for a set of ”OK words” (OK words are, words that have the label “Good” always regardless of AI results) to be excluded from the model’s input. This helps reduce unnecessary prediction load and makes the model more efficient.
|
1 2 3 4 5 6 7 8 9 10 |
# Read good words to be excluded from prediction process exclude_words = pd.array(df_exclude['words'].values) # Extract index of words to be excluded. indices = [] if exclude_words is not None: indices = np.where(np.isin(test_texts, exclude_words))[0] # Removing excluded words from input. This input will go to Model.Predict() test_texts = np.delete(test_texts, indices) |
2. The next step is to pre-process the input. First, we do the “tokenizing” process here, loading the tokenizer and then pre-process data for the model.
|
1 2 3 4 5 |
# Load tokenizer from tokenizer.pickle tokenizer = self.char_cnn_model.loadTokenizer() # Step 2 : Pre-process Data for Model logger.info('Tokenizing input data...') test_data = self.char_cnn_model.tokenizeInputData(tokenizer, test_texts) |
After that we pass the tokenized 2D vector array to the model and call the model’s predict() method. But before that we must build the model and train it!!
Build model
To build the model we define the number of layers and activation function. The activation function is responsible for deciding whether a node has to be activated or not depending on the weight assigned to it. Finally, in the output layer the weights are passed into a probability function which calculates the probability of the input belonging to a class. In our model, there are only 2 classes – Good and Bad. So the probability function gives the probability of the input for both classes.
Example – “This is a good sentence.”
So the probability function will give output as – (0.9, 0.1)
Where 0.9 is the probability of the sentence falling into the “Good” Class and 0.1 is the probability of the sentence falling into the “Bad” class.
We then train the model with the training data set of labelled texts.
We also sent a testing data set file to the model to calculate the testing accuracy. To find maximum accuracy, we tweaked certain parameters such as the “number of epochs” and “dropout percentage”. Once the model is trained, it is saved as a .h5 file.
We chose the .h5 file format as it stores everything such as weights, losses, optimizers used with keras in a single file. After saving the model, we can simply load the model and call predictions on the input texts. A saved model gives consistent results.
A small snippet of code for building model is added below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# Build model model = Model(inputs=inputs, outputs=predictions) model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy']) # Adam, categorical_crossentropy model.summary() # Training model.fit(x_train, y_train, validation_data=(x_test, y_test), batch_size=128, epochs=5, verbose=2) # saveModel model.save('/usr/local/analysis-text-classification/ai_model/SavedModel/charCNNgmoTest.h5') print("Model Saved!") |
3. The model makes predictions and stores them in a dataframe object. We also take care of the predictions for the excluded words. We fixed it to a value of [0.5, 0.5].
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# Load Pre-Trained model saved in .h5 format saved_model = self.char_cnn_model.loadTrainedModel() # Step 3 : Predict and return result logger.info('Calling AI Model for predictions...') predict_x = self.char_cnn_model.getPrediction(test_data, saved_model) # Adding prediction for Excluded words predict_x_full = [] counter = 0 for i in range(len(output_test_texts)): if i in indices: # Good prediction is added for excluded words predict_x_full.append([0.50000, 0.00000]) else: predict_x_full.append(predict_x[counter].astype(float)) counter += 1 |
We then output the prediction results along with the input texts in another .csv file. This file is then sent back to the MO server to read and display the results back to the user.
|
1 2 3 4 5 |
# Step 4 : Write result in Csv logger.info('Getting predictions ouput file...') self.char_cnn_model.getResultCsv(output_test_texts, predict_x_full, file_name) logger.info('Output File Path : %s', self.char_cnn_model.results_dir + file_name + '.csv') |
And with that the process comes to an end where all the Free Answers have successfully been classified by using AI.
Result
The CNN AI Model predicts well with a Kappa value of 0.8!
This model is faster to train and once trained, can be used any number of times to make predictions. Compared to AutoML, this is a better solution as we are able to achieve good results with minimum cost, hence a better total output.
The final result after last training cycle was obtained from the confusion matrix below –
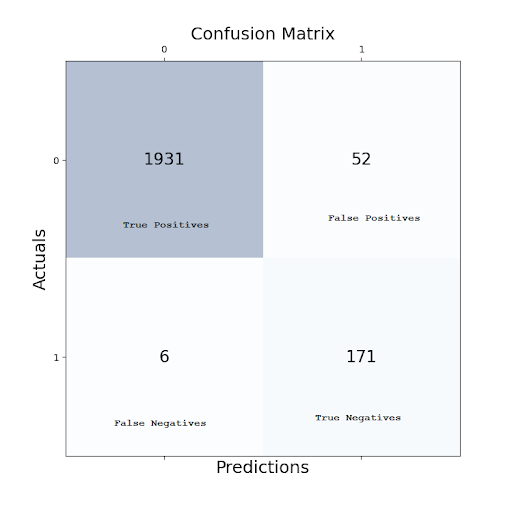
For a traditional 2×2 confusion matrix, the Cohen’s Kappa coefficient can be calculated as follows –
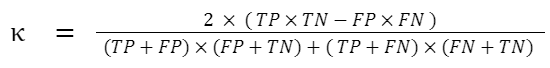
% of agreement: 97.31%
Cohen’s k: 0.840419
Further Improvements
* To further improve the space and time usage of the model, we used the technique of “Pruning” to prune out the unnecessary weights from the model since we are only using it for prediction.
* Pruning effectively reduces the weight of the model approximately by 3 times.
* To reduce the prediction time, we shifted to a “c5 instance” of the aws server machine, which provides better parallelization and utilisation of the CPU.
Conclusion
Using AI is a good choice to automate classification tasks to save manual work. This project demonstrated the use of a CNN Model for Japanese textual input which is classified into “good” and “bad” classes for the purpose of refining the quality of responses in a survey.
The project was tested thoroughly and then deployed into production for usage. The project received appreciation from the Operation Department as it successfully achieved the goal to reduce man hours and manual work.
The project was also given an award and the team members were given the award money. I was happy to work and deliver a product that was useful. It was a lovely experience and a great chance for me to learn Data Science techniques. I look forward to working on more such projects! Cheers!
Sources :
1. McHugh 2012 – (Source : https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3900052/)
2. Kappa Coefficient – https://www.datanovia.com/en/blog/kappa-coefficient-interpretation/
3. Tensorflow – https://en.wikipedia.org/wiki/TensorFlow
– https://www.tensorflow.org/tutorials
4. Keras – https://keras.io/



テックブログサムネ-3-730x410.jpg)
テックブログサムネ-4-730x410.jpg)
テックブログサムネ-2-730x410.jpg)