

こんにちは、システム部の岡崎です。
今日はスペシャルパネル(※)統合プロジェクト(※)における、性能改善と失敗事例を紹介していきたいと思います。
※スペシャルパネルとは、特定の条件を持つアンケートモニターを事前に把握して、その内容をデータとして貯めておくような機能のこと。例えば「トヨタの車を持っている人」という特別な属性のモニターをターゲットにアンケートを配信したい場合などに役立つ。以下スペパネ
※毎年個別に収集していたスペシャルパネルアンケートの回答を統合して、モニターの最新の回答が常に参照できるようなDBを構築するプロジェクト
[Redis] Set型とList型でのメモリ使用量の違い
RedisにはSet型とList型というものがあるのですが、RedisでSet型を使うとList型に比べてメモリ使用量が10倍多くなるということがやってみて分かりました。
そもそもRedisが何者かというと、 KVS(Key Value Store)であるKeyに対して値をSetできるデータベースのようなものになります。
このValueの形式として、Set型(順番は不定で重複値NG、集合演算値の集合)とList型(arrayやList同様順番が担保されていて、重複値OK)があり、このSet型を使うとかなりメモリ使用量が増えるのです。
何があったか
社内のスペパネAPIをリニューアルする際に、Search APIのバックエンドをRedisにしました。
スペパネの、「あるアンケートのある設問のある回答に答えたモニターはこの人です」というデータが、全部このバックエンドのRedisに入ってます(昔はHBaseでしたがリプレイスしました)。
ある設問のある回答に回答したモニターの集合演算(モニターID集合のANDやORを多階層で実行する)をしてユニークなモニターIDリストを生成したいってなった時、Redisに論理演算をやらせればいいのではないかと思い、初めSet型でトライしてみました。
すると、Redisにインスタンスを作成し、SetでどんどんIDを入れて行ったら、あっという間にメモリオーバで落ちてしまいました・・。
調査の結果、少量のデータであればSet型でも問題なく集合演算可能なのですが、大量のデータを扱うとなるとList型で入れて、集合演算はアプリ側にさせないと成り立たないということがわかりました。
どうやって解決したか
ということで、最終的には、大量に集合演算する日付範囲設問以外を、List形式にしてアプリ側(Kotlin)で集合演算をすることにしました。
これでメモリ問題は解決したが、さらにその後問題が・・
[Kotlin] Set型のmergeはまとめて実行すべし
次に、KotlinのSet型のmergeは都度都度実行せずまとめて実行しないと、めちゃくちゃ遅くなるということが分かりました。
なので複数のSet型の集合をmergeする時はまとめてあげた方が良さそうです。
(ちゃんと確認していないのですが汗、多分List型も同じじゃないかなと思います。)
何があったか
Set型の変数にモニターIDリストを代入する->マスターのSet型変数にマージする->作る->マージする->作る-> …を繰り返すと、サイズが増えるごとにどんどん遅くなりました・・。
コードでは、for eachでグルグル回りながらモニターのリストをAPIからもらって、都度都度ユニオン。
最終的に全てユニオンされた結果を返す、みたいなことをやってました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
/** * */ fun getMonitorSet(keys: List<String>): Set<String> { val allMonitors = mutableSetOf<String>() keys.forEach { allMonitors.union(getMonitorSet(it)) } return masterSet } /** * */ fun getMonitorSet(key: String):Set<String> { return getMonitorList(key).toSet() } |
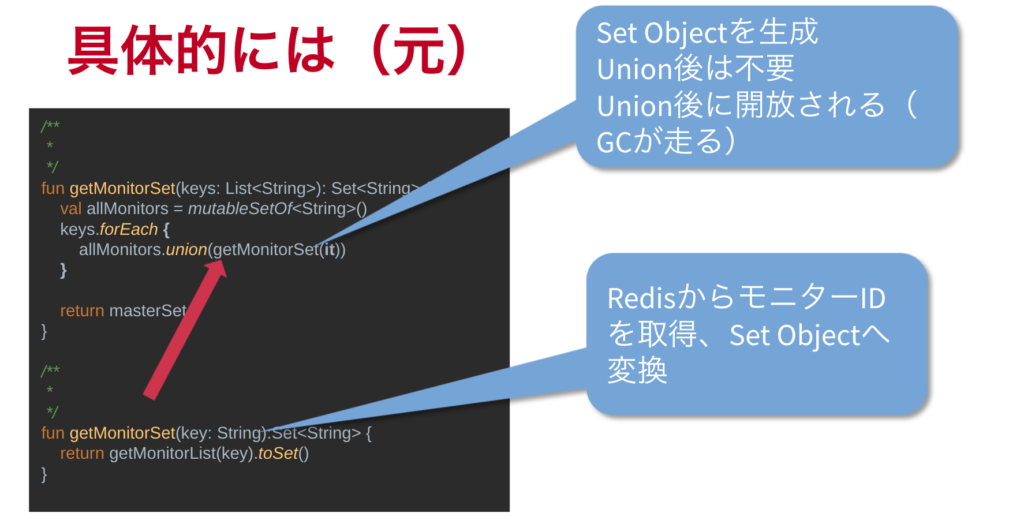
この裏で何があったのか。
DataDogでタイムラインを確認してみると、for eachで一度回って、Redisから持ってきてmergeするごとにGCがガンガン走っていることが分かりました。
GC祭り・・・・GC減らさねば・・・・・。
どうやって解決したか
そこで、メモリ回復しなければGC走らないようになるのでは?と考え、持つListを宣言しておいて、ただそこにどんどん追加していくだけ。最後に全部まとめてユニオンしてやる。というような処理にトライしてみました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
/** * */ fun getMonitorSet(keys: List<String>): Set<String> { val monitorLists =mutableListOf<List<String>>() keys.forEach { monitorLists.add(getMonitorList(it)) } return monitorLists.flatten().toSet() } /** * */ fun getMonitorList(key: String):List<String> { return getMonitorList(key) } |
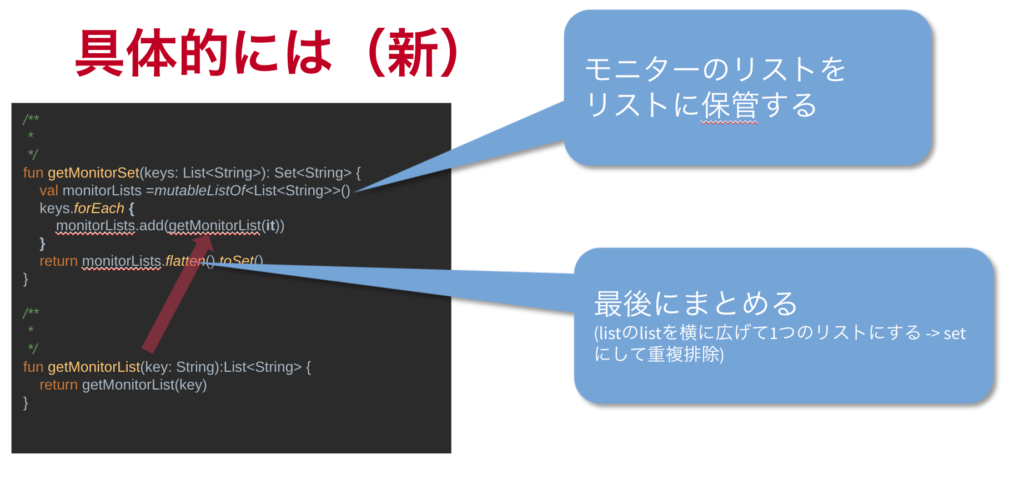
すると、その前まで何十秒もかかっていたのが、数百msまで時間短縮されました!
mergeをまとめたことで、GCが最後の1回だけ走るようになったのが大きいです。
都度都度Listをmergeするのはあまり得策ではないみたいなので、大量にやるときは考えた方が良さそうです。
[Redis] レンジキーが多すぎるとタイムアウトする
次に、RedisでSetを使い集合演算する際、結合するValueが多すぎるとTimeoutするということが分かりました。
何があったかというと・・
スペパネの裏側のRedisの話です。
スペパネでモニター検索を行う際、日付のレンジ(例:2020年1月1日〜2020年12月31日に回答した人)を指定することが可能になっています。
そのため「◯年◯月◯日」という各日付に回答した人のモニターのリストがあり、例えば一年分だったら365日分のキーがあるので、その日付毎に回答したモニターがRedisに格納されています。
2020年1月1日〜2020年12月31日までのレンジを指定された時、その期間で回答したモニターIDのリストをまとめて持っていきたいと考えました。
その場合、キーの数がかなり多くなってしまい、100個以上指定してユニオンでまとめて持ってこようとすると時間がかかりすぎてタイムアウトで落ちてしまう、ということがありました。
Redisのコネクションは、レスポンス重視で作られているものなので、あまり時間をかけすぎると途中でコネクションを切ってしまう仕様になっています。
コネクションの切断時間がデフォルトで1秒になっているのですが、AWSの場合だとこれを上手く変えられなくて結局1秒のままなので、大量にキーを指定してしまうと途中で落ちてしまうという事象でした。
どうやって解決したか
結局、キーを100個以上指定すると落ちてしまうので、いくつかに分割して(例えば50とか80とか)プログラム側でmergeしています。
ということで、集合演算使うときはやっぱりRedisには注意しましょう。
バリューやキーの量があまりに多すぎて取得に時間がかかるような使い方は出来るだけ避けた方がいいかなと思います。
現実的な大量データを使ったテストは、ぜひ1回は実行しておきましょう。
[Python] RedshiftへのSelect回数を減らす
次に、Redshiftへの検索回数を減らした方が良さそうだということが分かりました。
RedshiftはMySQLと異なり、巨大なSQLを実行したときでも処理がそこまで遅くなく、割と少ない実行時間で返してくれます。
ただし、Redshiftでは一回の検索に対するオーバーヘッドが結構大きいです。
そのため出来るだけRedshiftの検索は回数を減らしましょうという話です。
何があったか
「アンケートのある回答に回答したモニターを検索する処理」を実行しようとした際、下記の処理に4時間近くかかってしまいました・・。
すべてのアンケート回答結果個別に回答したモニターIDをRedshiftから検索(例えば、設問Aに1と回答したモニターリストを検索)
この設問にこの回答をしたモニターはこの人達です。という情報をRedisへ書く(Keyは“設問_回答”、ValueはモニターIDのリストでRedisへ書き込む)
元々のプログラムでは設問の個数分グルグル回りながら実行しています。
Redshiftから検索してRedisに入れる処理を設問×選択肢の個数分やっており、これに4〜5時間かかっていました。
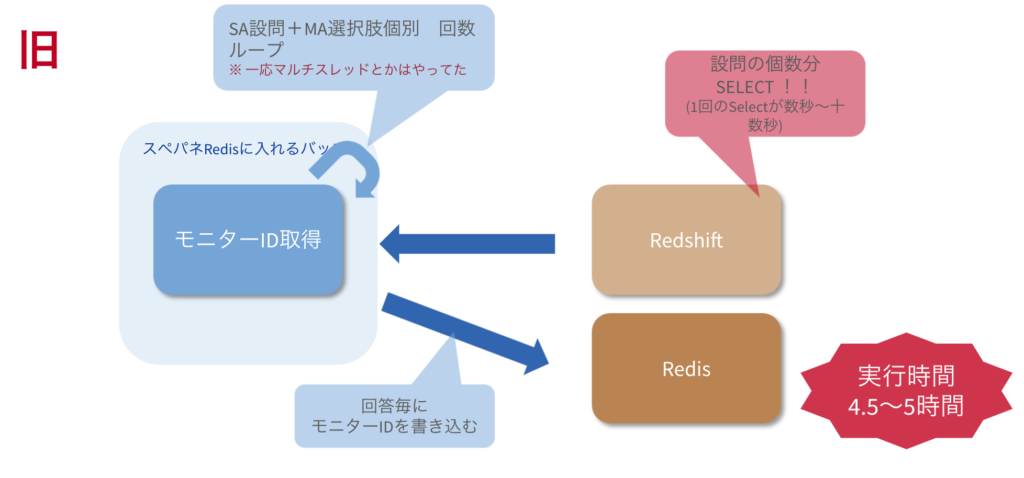
そこで、もっと早く終わらせられないか?ということにトライしていきました。
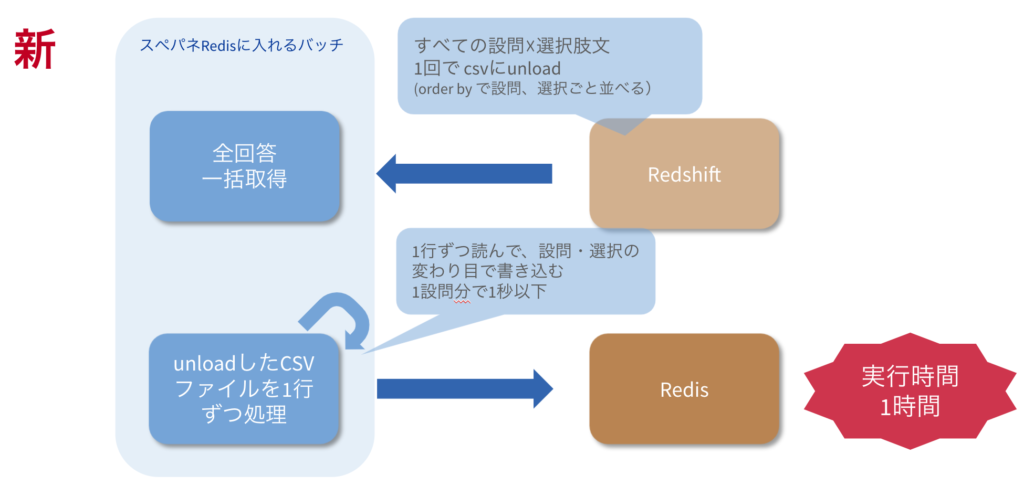
どうやって解決したか
一旦CSVに全設問分のデータをダウンロードしてしまい、プログラムで一行ずつ読み込んでRedisに入れた方が早くなるのでは?という仮説を立てました。
すると実行時間が1/5まで減り、1時間くらいで終わるようになりました。
Redshiftに何千回もSelectしに行くくらいなら、一度のSelectで全件読み込み、あとはプログラムで頑張った方がはるかに高速になります。
更にもうひとつ、この改善を行っている際に判明したことがあります。
Pandas Dataframeを使っていたのですが、RedshiftからダウンロードしてきているCSVの読み込みをPandasに任せてしまおうと考えました。
Pandas Dataframeを作ってそこから一行ずつ取り出して、モニターIDのリストを作ってRedisに入れようという算段です。
すると、このPandas Dataframeから一行ずつ取り出す処理はめちゃくちゃ遅い・・ということがわかりました。
なぜかというと、Dataframeから1行取り出すということはDataframeからSeriesObjectを生成する処理となるため、大量に実行するとそれだけで大きなオーバヘッドになるからです。
そのため、普通にテキストとして1行呼んで “,” でスプリットしてやったら10倍高速になりました。
Pandasだと一括してDataframe内を更新するような処理は早いですが、一行ずつ読み出して処理するとかは向いてなさそうですね。
補足)Redshiftで検索する際の注意
- 検索SQLが複雑で中間テーブルが生成する場合、Redshiftの残りDiskが不足して、Queryが実行できない場合があるので注意(中間テーブルは非圧縮で保存されるためがんがんDiskが消費される)
- Copyでデータをロードするときも同様、copy中は読み込まれたデータは圧縮されないので、Diskの残りの容量に注意。Copy完了後は圧縮されてdiskが空く
[Python] Pandasデータフレームのmergeは高速で便利
さて、最後にご紹介するのが、高速で便利なPandas Dataframeのmergeについてです。
こいつは非常に便利なのでぜひとも使っていきましょう。
何があったのか
Dataframeはエクセルの表みたいなもので、二次元配列みたいなものです。
それを一行ずつ更新するとなった時、ある条件に合っていたら、ある場所にある値を入れますっていう処理を、ある値の数だけ繰り返すっていうプログラムを最初書いていました。
世の中にあるサンプルを参考にしてやっているとおそらくこんな感じになるでしょう。
|
1 2 3 4 5 |
df.loc[ (df[‘original_question_id’] == ある値) & (df[‘original_answer’] == ある値), 'question_id' ] = ある入れたい値 |
これをループして毎回Dataframeの処理をしてPythonに戻ってくる・・という処理を何回もやると、やはり、ライブラリとPythonのインタプリタの間で処理が切り替わる際のオーバーヘッドも多くなってしまいます。
どうやって解決したか
一項目ずつの更新は結構時間がかかるので、できるならこれは一括でやりたい・・ということで同じチームの宮島さんに調査をお願いした結果、mergeというメソッドがあることが分かりました。
元々の値を、ある値と入れたい値を対にしたDataframeを最初に作ってしまって、Dataframe同士でmergeさせて一括で終わらせてしまうとかなり高速で終わります。
これ以外にも回収箇所はあったのですが、1.5時間かかっていた処理が20分以下で終わるようになりました。
|
1 2 3 4 |
df = df.merge(mappings_df, how='left', left_on=['original_question_id', 'original_answer'], right_on=['original_question_id', 'original_answer'], suffixes=['', '_right']) |
今回の改善で、Dataframeを使うときは、ループしながら一項目ずつ更新していくよりも、今回のmergeのような便利なメソッドを探して一括で更新できると高速に動くということが分かりました。
PandasはPythonのライブラリですが中身はゴリゴリのC言語なので、Dataframeに全部渡してやってもらう方が高速に動きます。
今回のmergeのような便利なメソッドが存在するのであれば、それを利用する方がかなり性能が向上するので、ぜひ探してみてみてください。
以上となります。
読んでいただき、ありがとうございました。



テックブログサムネ-3-730x410.jpg)
テックブログサムネ-4-730x410.jpg)
テックブログサムネ-2-730x410.jpg)