

皆さんこんにちは。私はGMOリサーチのグローバルシステム部に所属するロヒートと申します。私の仕事は、市場とお客様の橋渡しをするためのシステムを構築・維持することです。私は入社して約2年目で、新しい機能を開発したり、マーケティングソリューションプラットフォームで世界でNo.1になるという同じ目標を持つ仲間と一緒に仕事をするのが好きです。
※本記事のオリジナル版(英語)はこちらになります。
プロジェクトの背景
2022年の年明けにマネージャーから、私が新しいプロジェクトに携わることになったよというメッセージをもらいました。その報告を聞いて、私はわくわくしました。プロジェクトの仕事は、計画と実行のサイクルが必要なので、私は好きです。「計画を立て、実行」とは点検し、その間で変更が必要ならまた計画し、実行するというサイクルを繰り返すことです。 私は、ゴールを考えそこに至るまでのステップを見ることは面白いと思っています。これは、GMOのスピリットベンチャー宣言「結論ファースト」から学んだことです。
すぐに、私はプロジェクトの詳細を知ることになりました。このプロジェクトは、日本語の文章を読んで処理し、その文章の良し悪しを判断するシステムを開発するというものでした。このプロジェクトは、コンピュータが理解できない特殊な言語の文章を理解するアルゴリズムが必要で、NLP(Natural Language Processing:自然言語処理)というカテゴリーに入ります。NLPとは人工知能の一種で、コンピュータが人間と同じように言語を理解する能力です。言語を理解するためには、膨大な語彙から単語の組み合わせまで、さまざまなステップがあります。そのためには、言葉の裏にある意味や感情を理解し、良し悪しを分類することが大切になります。まずは、このプロジェクトの詳細を見ていきましょう。
プロジェクトの詳細
FAチェック自動化とは?

そこで、これらの自由回答を自動でチェックしようというプロジェクトが始まりました。人がすべての回答を1つずつ読んで、回答の適切さをチェックするのは大変な作業です。
人が手作業ですべての自由回答をチェックし、検証するとなると数百時間かかるでしょう。ですが、もし機械がそれを行うことができれば、チェックが自動化され、その百時間の工数をもっと生産的なことに使うことができるようになります。「時間活用の改善」これが、このプロジェクトの最大の動機です。
プロジェクトの解決策
プロジェクトが理解できたら、次は解決策を考えます。
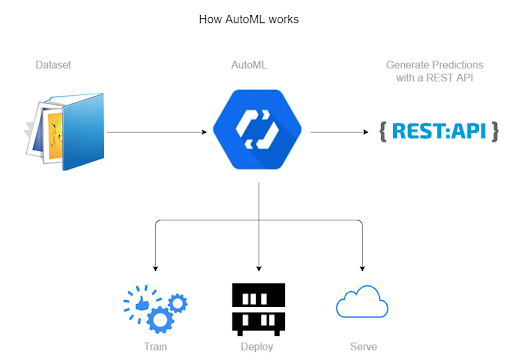
私たちはまず、GoogleのAutoML(自動化された機会学習)機能の調査を開始しました。これは、正しいラベルを付けたユーザーの入力を機械学習モデルに与え、パターンを理解させる仕組みを備えるものです。一度ラベル付きの入力でモデルを学習させてしまえば、ラベル付けされていない入力をモデルに与えても、モデルは良し悪しをラベルで分類した出力テキストで返答します。
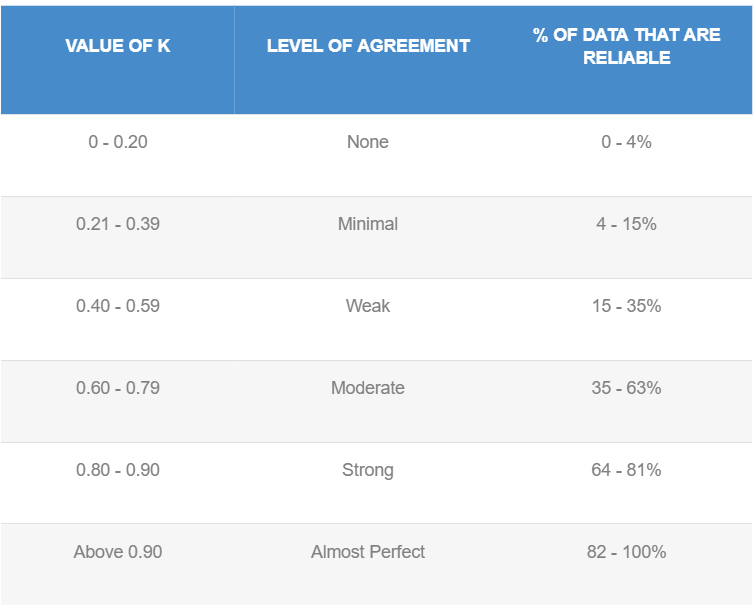
「カッパ係数」:2つの異なる事象に収集された2つのデータセットの頻度間がどれほど一致するのか、カッパ係数によって技術的に理解することができます。この係数は、実際の予測値と期待される予測値の関係をよく表すものです。
1. 学習時間が非常に長い。
2. より多くのデータセットに対してAutoMLを実稼働で使用するためのコストが高い。
3. 結果はまずまずであったが、カッパ相関係数値の条件として、よりよくする必要性がある。 当初得られたカッパ係数値は低かったのですが、最終的に中程度の一致である約0.6に近づけることができました。
そこで、他の解決策を探し始めました。
興味深い事実として日本語は他の言語と異なり、すべての単語がスペースなしで連続的に書かれています。また、入力されたテキストの文字列を、入力テキストからすべての文字とその組み合わせをマッピングした2次元ベクトル配列に変換する「トークン化」という処理も必要です。そのため、文章を単語を区切って理解することが難しいのです。文章から個々の単語を分離する有名なトークナイザーもありますが、同じ文章を処理するのに処理時間が長くなり、より多くのメモリを使用することになります。
そこで、文字レベルで動作するCNN(Convolutional Neural Networks)を用いることにしました。この方法では、テキストを分類するために言語の意味や構文に関する知識を必要としません。これは特に日本語の場合、単語の分解が不要になり、よりシンプルな実装が可能になります。各文字を読み取り、他の文字との組み合わせを学習すると、学習データに基づいたラベルが含まれている完璧な文章かどうかの確率を計算で求めることができます。
このCharacter Level CNNモデルは、TensorflowとKerasを使用して構築することになりました。
TensorFlowはオープンソースのエンドツーエンドプラットフォームで、複数の機械学習タスクのためのライブラリであり、KerasはTensorFlow上で動作する高水準のニューラルネットワークライブラリです。
どちらもモデルの構築や学習を簡単に行うためのハイレベルなAPIを提供していますが、KerasはPythonを内蔵しているため、より使い勝手が良いのが特徴です。
TensorflowとKerasを使うのは初めてだったので、モデルを効率的に活用し、正確な結果を出すために実装前にしっかりと勉強する必要がありました。
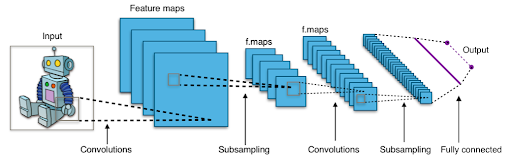
Source : https://en.wikipedia.org/wiki/Convolutional_neural_network#/media/File:Typical_cnn.png
プロジェクト作業の流れ
1. 私たちの最初のタスクは、入力を理解することでした。MO(マーケットオブザーバー)と同じように、Tensorflow Modelにも対応させることが必要でした。そこで、改行文字で区切られたテキストを含む.csvファイルを使用することにしました(\n)。このファイルはMO Analysis(回答データを処理するシステム)によって生成され、AI Modelサーバーへ送られ、予測を行います。
AIモデルサーバーでは、PythonのPandas Libraryを使ってcsvを読み込み、テキストをdataframeオブジェクトに保管します。csvファイルが大きすぎる場合は、メモリのオーバーフローを防ぐためにチャンク形式で読み込まれます。
|
1 2 3 4 5 6 7 8 9 10 11 |
# Read CSV in chunks dfs = pd.read_csv(file_path, names=['sentence'], sep='\n', engine='python', skip_blank_lines=False, na_filter=False, encoding='utf-8', iterator=True, chunksize=int(self.char_cnn_model.chunk_size)) for df in dfs: if df.empty: logger.error('File : %s is empty!', file_path) return -1 test_texts = np.array(df['sentence'].values) output_test_texts = test_texts |
また、「OKワード」(AIの結果に関わらず、常に「良い」というラベルが貼られているワード)をモデルの入力から除外するように設定しました。これにより、無駄な予測負荷を減らし、モデルをより効率的にすることができます。
※OKワードとは「なし」「特になし」などのアンケート回答時に使われる一般的なワードのことです。
2. 次のステップは、入力の前処理です。まず、ここでは「トークン化」処理を行い、それを読み込んでから、モデルのデータ前処理を行います。
|
1 2 3 4 5 6 7 |
# Load tokenizer from tokenizer.pickle tokenizer = self.char_cnn_model.loadTokenizer() # Step 2 : Pre-process Data for Model logger.info('Tokenizing input data...') test_data = self.char_cnn_model.tokenizeInputData(tokenizer, test_texts) |
その後、トークン化された2Dベクトル配列をモデルとして通過させ、モデルのpredict()メソッドを呼び出します。しかし、私たちはその前にモデルを構築し、学習させる必要があります!
モデルの構築
モデルを構築するために、レイヤーの数と活性化関数を定義します。活性化関数は、ノードに割り当てられたウェイトに応じて、ノードを活性化するかどうかを決定する役割を持っています。最後に、出力レイヤーでウェイトは確率関数に渡され、データが分類に属する確率を計算します。このモデルでは、「良い」「悪い」の2つの分類しかありません。従って、確率関数はデータが両方の分類に属する確率を生みだします。
良いモデルの例
確率関数は次のように出力します – (0.9、0.1)
ここでの0.9はその文章が「良い」分類に入る確率、0.1は「悪い」分類に入る確率です。
そして、ラベル作成された文言のトレーニングデータセットでモデルに学習させます。
また、テスト用のデータセットファイルをモデルに送り、テスト精度を計算しました。最大精度を求めるために、「エポック数」や「ドロップアウト率」など、特定のパラメータを微調整しました。モデルの学習が完了すると、.h5ファイルとして保存されます。
.h5ファイル形式を選んだのは、kerasで使用するウェイト、損失、最適化などすべてを1つのファイルに保存するためです。モデルを保存した後は、そのモデルをロードして、入力テキストに対して予測を呼び出すだけで良いです。保存されたモデルは、一貫した結果をもたらします。
下記に、モデル構築のための簡単なコードを追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# Build model model = Model(inputs=inputs, outputs=predictions) model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy']) # Adam, categorical_crossentropy model.summary() # Training model.fit(x_train, y_train, validation_data=(x_test, y_test), batch_size=128, epochs=5, verbose=2) # saveModel model.save('/usr/local/analysis-text-classification/ai_model/SavedModel/charCNNgmoTest.h5') print("Model Saved!") |
3. モデルは予測を行い、それをdataframeオブジェクトに保管する。また、予測を除外された単語に対しては、[0.5、 0.5]の値を固定で設定するようにしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Load Pre-Trained model saved in .h5 format saved_model = self.char_cnn_model.loadTrainedModel() # Step 3 : Predict and return result logger.info('Calling AI Model for predictions...') predict_x = self.char_cnn_model.getPrediction(test_data, saved_model) # Adding prediction for Excluded words predict_x_full = [] counter = 0 for i in range(len(output_test_texts)): if i in indices: # Good prediction is added for excluded words predict_x_full.append([0.50000, 0.00000]) else: predict_x_full.append(predict_x[counter].astype(float)) counter += 1 |
次に、予測結果を入力テキストと一緒に別の.csvファイルに出力します。このファイルをMOサーバーに送り返し、結果を読み込んでユーザーに表示します。
|
1 2 3 4 5 |
# Step 4 : Write result in Csv logger.info('Getting predictions ouput file...') self.char_cnn_model.getResultCsv(output_test_texts, predict_x_full, file_name) logger.info('Output File Path : %s', self.char_cnn_model.results_dir + file_name + '.csv') |
そして、すべての自由回答がAIによって分類されたところで、このプロセスは終了します。
結果
CNN AIモデルは、カッパ値0.8と非常に良い予測をするようになりました!
このモデルは学習が速く、一度学習すれば何度でも予測に使用することができます。
AutoMLと比較すると、最小限のコストで良い結果を得ることができるため、より良い結果であると言えます。
最後の学習サイクル後の最終結果は、以下の混同行列から得られました。
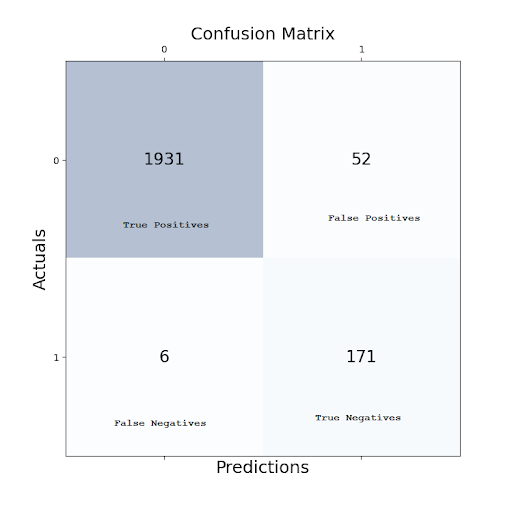
1931 (True Positives) + 171 (True Negatives) = 2102
6 (False Negatives) + 52 (False Positives) = 58
従来の2×2混同行列の場合、Cohenのカッパ係数は次のように計算できます。
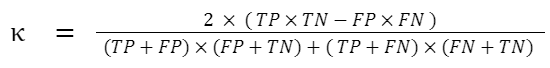
% of agreement: 97.31%
Cohen’s k: 0.840419
さらに改善
* 予測にのみ使用するため、不要なウェイトを削除する「プルーニング」という手法を用い、モデルの容量と使用時間をさらに改善しました。
* 剪定により、約3倍の軽量化を実現しました。
* 予測時間を短縮するために、CPUをより並列化・活用しやすいawsサーバーマシンのc5インスタンスに移行しました。
結論
分類作業を自動化し、手作業を減らすには、AIを使うのが良い選択です。このプロジェクトでは、CNNモデルを用いて、日本語のテキスト入力を「良い」クラスと「悪い」クラスに分類し、アンケートの回答品質を向上させることを実証しました。
プロジェクトは十分にテストされ、その後、本番環境に導入され使用されました。このプロジェクトは、工数削減と手作業の削減という目標を見事に達成し、オペレーション部から高い評価を受けました。
また、このプロジェクトは表彰され、チームメンバーには賞金が贈られました。自分が働いたことで、役立つ成果物を供給できたことが嬉しかったです。素敵な経験でしたし、データサイエンスの技術を学ぶ良い機会になりました。これからも、このようなプロジェクトに参加できることを楽しみにしています。Cheers!
引用 :
1. McHugh 2012 – (Source : https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3900052/)
2. Kappa Coefficient – https://www.datanovia.com/en/blog/kappa-coefficient-interpretation/
3. Tensorflow – https://en.wikipedia.org/wiki/TensorFlow
– https://www.tensorflow.org/tutorials
4. Keras – https://keras.io/
テックブログサムネ-1-730x410.png)




