

みなさんこんにちは、システム部の岡崎です。今回はBigQueryのSQLだけでRAGを作ってみようと思います。
RAG(Retrieval-Augmented Generation)とは?
質問に対して関連する情報を検索し、その情報を基に回答を生成する自然言語処理の手法です。
Chat GPT
検索(Retrieval)と生成(Generation)を組み合わせることで、より正確で詳細な回答を提供する仕組みのことです。
Q&Aチャットや、社内文書の検索などで見かけますが、中でもLangChain, Llama index の pyhton framework が有名です。
BigQuery MLでLLMが使える
ある日、BigQuery ML について色々調べていると。。。
BigQuery上で大規模言語モデルを扱える関数がある!
ML.GENERATE_TEXT (テキスト生成)
ML.GENERATE_TEXT_EMBEDDING(テキストのベクトル化)
他にも。
ML.DISTANCE (2つのベクトル間の距離を計算)
これだけあればSQLだけで RAG が作れるのではないか?と思い、試してみることにしました。
処理の概要を考えてみる
処理の概要として、以下のステップを考えました。
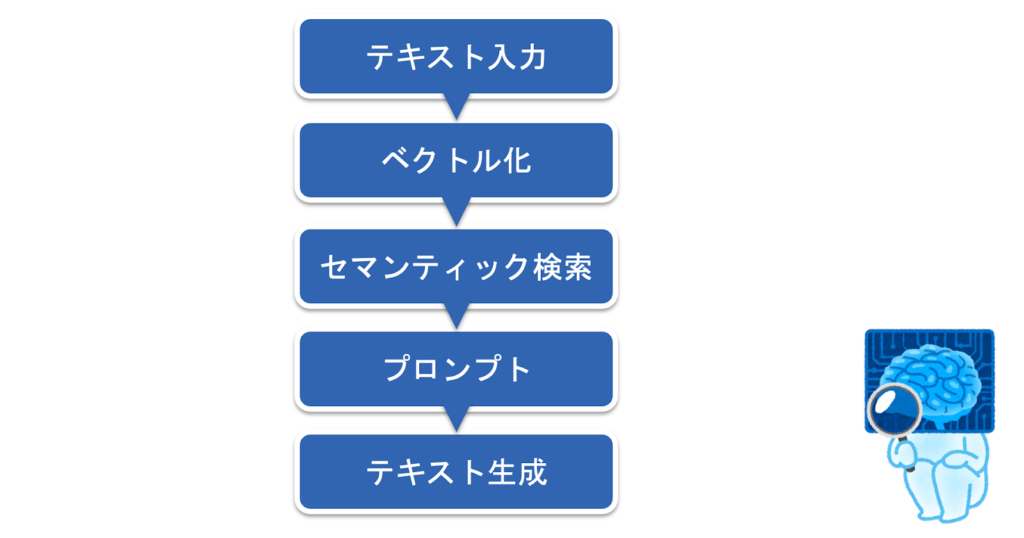
まずは下準備
BigQueryからBigQuery外のリソースにアクセスするためのコネクタを作ります。
bq コマンドを使用します。
bq mk --connection \
--location=asia-northeast1 \
--project_id="okazaki-data-project" \
--connection_type=CLOUD_RESOURCE "vertex_ai_connection"BigQueryで使用モデルの定義を追加します。
BigQuery Studio などからSQLを実行します。
【悲報】現時点では、Googleが23年12月に発表した新AIの「 Gemini」は使用できませんでした。。。(2024年1月26日現在)
create or replace model sql_rag.embeding_model
remote with connection asia-northeast1.vertex_ai_connection
OPTIONS (ENDPOINT = 'textembedding-gecko-multilingual@001');
create or replace model sql_rag.generate_text_model
remote with connection asia-northeast1.vertex_ai_connection
OPTIONS (ENDPOINT = 'text-bison-32k@002')
予備知識データベースのベクトル化
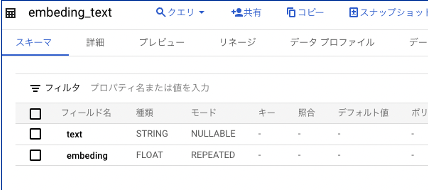
テーブルを作ります。
こちらがベクトル化する文字列と、ベクトルを格納する Float(Repeateds) 型の構成です。
テーブルのupdateでベクトル化します。
ベクトル化には ML.GENERATE_TEXT_EMBEDDING 関数を使用します。
Update1発で全件ベクトル化できるのは便利です。
UPDATE sql_rag.embeding_text AS e
SET embeding = ( SELECT text_embedding FROM
ML.GENERATE_TEXT_EMBEDDING(
MODEL sql_rag.embeding_model,
(SELECT e.text as content),
STRUCT(TRUE AS flatten_json_output)
))
WHERE true
セマンティック検索
入力された文字列をベクトル化します。
前項で作ったテーブルを検索しベクトル距離が近いテキストを取得します。
ベクトルの距離の算出に ML.DISTANCE 関数を使用します。
WITH input_text_to_vector AS (
SELECT text_embedding FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL sql_rag.embeding_model,
(SELECT '複数の配列を接続する' AS content),
STRUCT(TRUE AS flatten_json_output)
)
)
SELECT text, ML.DISTANCE(text_embedding, e.embeding) as distance
FROM input_text_to_vector
CROSS JOIN (SELECT * FROM sql_rag.embeding_text) as e
ORDER BY distance
limit 3
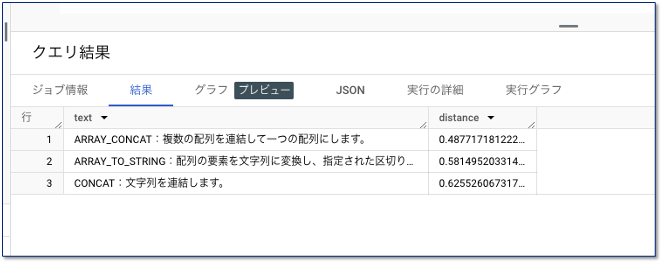
検索結果はこんな感じです。大体目論見通りの結果でした。
プロンプトを作る
次にLLMに入力するテキストを作ります。
SELECT
CONTACT(
‘コンテキストに示されている過去情報に従って質問に答えてください\n’,
‘明らかに関係ないコンテキストは無視してください\n’,
‘明らかに関係ないコンテキストは回答に含めないでください\n’,
‘できる限り最後まで言い切ってください\n\n’,
‘質問の内容が複数のコンテキストに合致する場合分割して回答してください\n\n’,
‘# 質問\n’,
‘複数の配列を接続する\n\n’,
‘# コンテキスト情報\n’,
‘・1行が1コンテキストになります\n’
‘------------------\n’,
ARRAY_AGG(text, ‘\n’),
‘------------------\n’
) AS content結果こんな感じになります。
コンテキストに示されている過去情報に従って質問に答えてください
明らかに関係ないコンテキストは無視してください
明らかに関係ないコンテキストは回答に含めないでください
できる限り最後まで言い切ってください
質問の内容が複数のコンテキストに合致する場合分割して回答してください
# 質問
複数の配列を接続する
# コンテキスト情報
・1行が1コンテキストになります
——————
ARRAY_CONCAT:複数の配列を連結して一つの配列にします。
ARRAY_TO_STRING:配列の要素を文字列に変換し、指定された区切り文字で連結します。
CONCAT:文字列を連結します。
——————
最後に Text Generation
最後に回答となるテキスト LLMを使用して生成します。
SELECT ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT(
MODEL sql_rag.generate_text_model,
(SELECT content AS prompt FROM rag_prompt),
STRUCT(
0.2 AS temperature,
1024 AS max_output_tokens,
TRUE AS flatten_json_output));全部合体してRAGが完成
これまでのSQLをすべて合体して整理すると、こんなソースになります。
DECLARE question_text STRING;
SET question_text = '複数の配列を接続する';
WITH input_text_to_vector AS (
SELECT text_embedding FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL sql_rag.embeding_model,
(SELECT question_text AS content),
STRUCT(TRUE AS flatten_json_output)
)
)
,context AS (
SELECT text, ML.DISTANCE(text_embedding, e.embeding) as distance
FROM input_text_to_vector
CROSS JOIN (SELECT * FROM sql_rag.embeding_text) as e
ORDER BY distance
limit 3
),rag_prompt AS (
SELECT
CONCAT(
'コンテキストに示されている過去情報に従って質問に答えてください\n’,
'明らかに関係ないコンテキストは無視してください\n’,
'明らかに関係ないコンテキストは回答に含めないでください\n’,
'できる限り最後まで言い切ってください\n’,
'質問の内容が複数のコンテキストに合致する場合分割して回答してください\n\n’,
'回答はテキスト形式で回答してください。\n’,
'#質問\n’,
question_text, '\n\n’,
'# コンテキスト情報\n’,
'・1行が1コンテキストになります\n’,
'------------------\n’,
STRING_AGG(text, '\n’),
'\n------------------\n’
) AS content
FROM context
)
SELECT ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT(
MODEL sql_rag.generate_text_model,
(SELECT content AS prompt FROM rag_prompt),
STRUCT(
0.2 AS temperature,
1024 AS max_output_tokens,
TRUE AS flatten_json_output))
結果出力(例)
結果の出力はこんな感じになりました。
回答
ARRAY_CONCAT関数を使用します。
ARRAY_CONCAT(配列1, 配列2, …)
の形式で、連結したい配列を指定します。
例えば、以下の配列を連結する場合
配列1 = [1, 2, 3]
配列2 = [4, 5, 6]
ARRAY_CONCAT(配列1, 配列2)
とすると、以下の配列が返されます。
[1, 2, 3, 4, 5, 6]
- 今回は予想通りの結果が出ました。
- 使用例なんて、DBには入れていないにも関わらずちゃんと出てきてるのが面白いです。
- 質問文によっては頓珍漢な回答をされることもあります。これは当たり前といえば当たり前ですね。
感想
- BigQuerのSQLだけでRAGができたのは意外と便利
- SQLしかわからない人でも形にはできるかも。
- BIツール(Lookerなどなど)や、redash とかでもフロントになるので、外部提供するわけではなければ、これでも問題ないかも。
- Llama index とか使わなくても社内のサービスぐらいなら、使いようによっては。。
以上となります。
なんとなく思いつきでやってみましたが、思いの外応用できそうな部分があったので、今後の開発にもいかせていけたらなと思います。






